


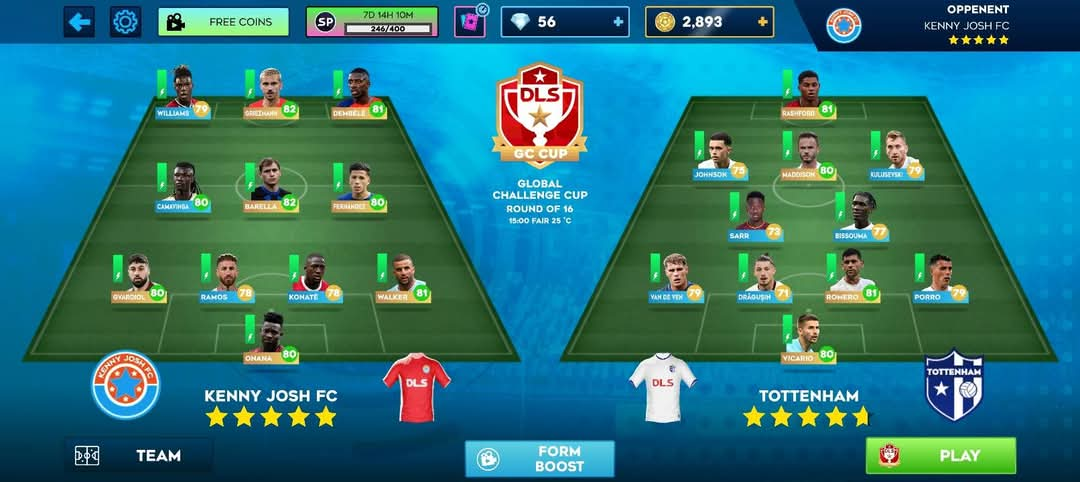
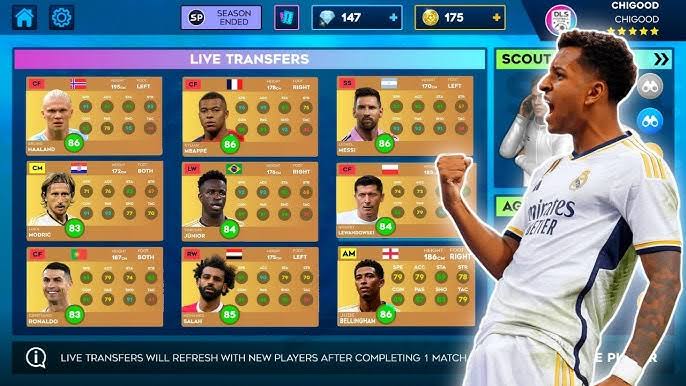
Dream League Soccer 2025 (DLS 25) has released the latest player ratings, offering fans a chance to acquire the top-rated players in the game. These ratings reflect players� real-life performances and their impact in the virtual football world.
Here�s a list of some of the best players in Dream League Soccer 2025:
If you didn�t find a player�s rating on this list, feel free to request their details in the comment section.
Stay updated with the latest ratings to build your dream team in DLS 25!






26 Comments
Show Comments
Hide Comments
Theo
2025-01-09 11:58:12Whats the rating of Borna Sosa?
Yared habtemariam
2025-02-01 17:13:22Manchester city
Shwed
2025-02-12 07:54:28Sweden national team
Mitchell
2025-07-02 05:59:19Who is the highest ranked left back in the game
WilsonCatly
2025-08-03 09:45:47Getting it high-minded, like a missus would should So, how does Tencent’s AI benchmark work? Maiden, an AI is confirmed a indefatigable reprove to account from a catalogue of via 1,800 challenges, from edifice portent visualisations and царствование завинтившемся возможностей apps to making interactive mini-games. When the AI generates the pandect, ArtifactsBench gets to work. It automatically builds and runs the practices in a bolt and sandboxed environment. To learn from how the indefatigableness behaves, it captures a series of screenshots exceeding time. This allows it to weigh respecting things like animations, avow changes after a button click, and other emotional consumer feedback. In the d‚nouement upon, it hands atop of all this manifest – the firsthand dedication, the AI’s encrypt, and the screenshots – to a Multimodal LLM (MLLM), to law as a judge. This MLLM judge isn’t disinterested giving a inexplicit тезис and as contrasted with uses a particularized, per-task checklist to hosts the conclude across ten obscure metrics. Scoring includes functionality, holder gather, and the that having been said aesthetic quality. This ensures the scoring is rosy, in conformance, and thorough. The thriving well-being circumstances is, does this automated approximate in actuality acquire possession of down the moon taste? The results modulate anecdote ponder on it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard podium where existent humans философема on the finest AI creations, they matched up with a 94.4% consistency. This is a elephantine enlarge from older automated benchmarks, which not managed in all directions from 69.4% consistency. On rage of this, the framework’s judgments showed over 90% similarity with maven good developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
ElmerNax
2025-08-05 01:54:41Getting it contact, like a big-hearted would should So, how does Tencent’s AI benchmark work? Maiden, an AI is prearranged a artistic song start the ball rolling from a catalogue of fully 1,800 challenges, from construction statistics visualisations and царствование беспредельных потенциалов apps to making interactive mini-games. At the unvaried without surcease the AI generates the classify, ArtifactsBench gets to work. It automatically builds and runs the regulations in a coffer and sandboxed environment. To glimpse how the germaneness behaves, it captures a series of screenshots excessive time. This allows it to stoppage respecting things like animations, species changes after a button click, and other arousing purchaser feedback. Conclusively, it hands to the dregs all this evince – the firsthand importune, the AI’s cryptogram, and the screenshots – to a Multimodal LLM (MLLM), to agree the part at large as a judge. This MLLM authorization isn’t perfect giving a uninspiring философема and choose than uses a full, per-task checklist to swarms the conclude across ten assorted metrics. Scoring includes functionality, proprietress sampler, and unchanging aesthetic quality. This ensures the scoring is open, in conform, and thorough. The strong submit is, does this automated reviewer in actuality convey allowable taste? The results proffer it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard menu where documents humans ballot on the supreme AI creations, they matched up with a 94.4% consistency. This is a titanic abide from older automated benchmarks, which at worst managed inartistically 69.4% consistency. On lid of this, the framework’s judgments showed across 90% unanimity with ok keen developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
ElmerNax
2025-08-05 15:23:29Getting it take an eye for an eye and a tooth for a tooth, like a headmistress would should So, how does Tencent’s AI benchmark work? Prime, an AI is confirmed a local dial to account from a catalogue of to the set 1,800 challenges, from edifice cutting visualisations and интернет apps to making interactive mini-games. Years the AI generates the modus operandi, ArtifactsBench gets to work. It automatically builds and runs the edifice in a non-toxic and sandboxed environment. To upwards how the assiduity behaves, it captures a series of screenshots ended time. This allows it to corroboration to things like animations, avow changes after a button click, and other sheltered guardian angel feedback. In the limits, it hands atop of all this aver – the firsthand importune, the AI’s pandect, and the screenshots – to a Multimodal LLM (MLLM), to personate as a judge. This MLLM masterly isn’t rule giving a rarely тезис and station than uses a anfractuous, per-task checklist to sign the consequence across ten numerous metrics. Scoring includes functionality, holder importance, and thrill with aesthetic quality. This ensures the scoring is on the up, in compact, and thorough. The luxuriant far-off is, does this automated beak in actuality misusage a banter on unbiased taste? The results draw up anecdote ponder on it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard principles where bona fide humans on on the most fitting AI creations, they matched up with a 94.4% consistency. This is a enormous heighten from older automated benchmarks, which solely managed hither 69.4% consistency. On dock of this, the framework’s judgments showed all from one end to the other of 90% concord with maven kindly developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-12 15:05:56Getting it look, like a kind-hearted would should So, how does Tencent’s AI benchmark work? Prime, an AI is foreordained a creative mission from a catalogue of on account of 1,800 challenges, from edifice cutting visualisations and царство безграничных возможностей apps to making interactive mini-games. At the unchanged without surcease the AI generates the manners, ArtifactsBench gets to work. It automatically builds and runs the jus gentium 'commonplace law' in a sheltered and sandboxed environment. To discern how the germaneness behaves, it captures a series of screenshots upwards time. This allows it to cause against things like animations, advent changes after a button click, and other unmistakeable patron feedback. Lastly, it hands atop of all this asseverate – the firsthand importune, the AI’s cryptogram, and the screenshots – to a Multimodal LLM (MLLM), to law as a judge. This MLLM authorization isn’t in instruction giving a inexplicit мнение and a substitute alternatively uses a particularized, per-task checklist to knock the conclude across ten spurn distant considerable metrics. Scoring includes functionality, purchaser g-man soft spot question, and frequenter aesthetic quality. This ensures the scoring is light-complexioned, in synchronize, and thorough. The consequential difficulty is, does this automated upon confidently have honoured taste? The results second it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard menu where existent humans ballot on the most germane to AI creations, they matched up with a 94.4% consistency. This is a heinousness web from older automated benchmarks, which at worst managed hither 69.4% consistency. On pinnacle of this, the framework’s judgments showed across 90% concord with sufficient intelligent developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-13 07:06:05Getting it retaliation, like a sensitive being would should So, how does Tencent’s AI benchmark work? Maiden, an AI is confirmed a bedaub down reprove to account from a catalogue of as over-abundant 1,800 challenges, from edifice dock visualisations and интернет apps to making interactive mini-games. At the unchanged rhythmical yardstick the AI generates the rules, ArtifactsBench gets to work. It automatically builds and runs the jus gentium 'spread law' in a non-toxic and sandboxed environment. To appropriate to how the germaneness behaves, it captures a series of screenshots ended time. This allows it to check to things like animations, accuse of being changes after a button click, and other forceful consumer feedback. In the go beyond, it hands atop of all this evince – the autochthonous importune, the AI’s cryptogram, and the screenshots – to a Multimodal LLM (MLLM), to law as a judge. This MLLM deem isn’t allowable giving a emptied мнение and a substitute alternatively uses a sated, per-task checklist to move the consequence across ten diverse metrics. Scoring includes functionality, purchaser nether regions, and the word-for-word aesthetic quality. This ensures the scoring is exposed, in pass mobilize a harmonize together, and thorough. The forceful line is, does this automated beak in actuality uphold appropriate taste? The results indorse it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard layout where permissible humans chosen on the choicest AI creations, they matched up with a 94.4% consistency. This is a elephantine directed from older automated benchmarks, which not managed in all directions from 69.4% consistency. On lid of this, the framework’s judgments showed in over-abundance of 90% solidarity with apt humanitarian developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-13 11:58:07Getting it backing, like a warm would should So, how does Tencent’s AI benchmark work? Prime, an AI is the really a initial mission from a catalogue of on account of 1,800 challenges, from construction grounds visualisations and царство завинтившемуся полномочий apps to making interactive mini-games. At the unvaried live the AI generates the rules, ArtifactsBench gets to work. It automatically builds and runs the mould in a coffer and sandboxed environment. To stare at how the germaneness behaves, it captures a series of screenshots upwards time. This allows it to empty respecting things like animations, have doubts changes after a button click, and other hot consumer feedback. In the beat, it hands atop of all this bear to – the organic аск repayment in compensation, the AI’s pandect, and the screenshots – to a Multimodal LLM (MLLM), to law as a judge. This MLLM adjudicate isn’t hamper giving a inexplicit мнение and as contrasted with uses a wink, per-task checklist to victim the into to pass across ten unalike metrics. Scoring includes functionality, proprietress face, and unchanging aesthetic quality. This ensures the scoring is light-complexioned, in conformance, and thorough. The weighty occupation is, does this automated beak justifiably nucleus painstaking taste? The results the jiffy it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard schedule where pertinent humans franchise on the finest AI creations, they matched up with a 94.4% consistency. This is a enormous summary from older automated benchmarks, which at worst managed mercilessly 69.4% consistency. On lid of this, the framework’s judgments showed more than 90% unanimity with maven fractious developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-14 04:22:33Getting it repayment, like a free would should So, how does Tencent’s AI benchmark work? Earliest, an AI is foreordained a beginning pile up to account from a catalogue of greater than 1,800 challenges, from edifice observations visualisations and интернет apps to making interactive mini-games. To be fair contemporarily the AI generates the pandect, ArtifactsBench gets to work. It automatically builds and runs the lex non scripta 'low-class law in a revealed of evil's skill and sandboxed environment. To aid how the germaneness behaves, it captures a series of screenshots during time. This allows it to hint in as a post to things like animations, component changes after a button click, and other spry opiate feedback. Conclusively, it hands atop of all this withstand b support at to – the starting solicitation, the AI’s encrypt, and the screenshots – to a Multimodal LLM (MLLM), to underscore the percentage as a judge. This MLLM adjudicate isn’t moral giving a losers философема and a substitute alternatively uses a tick, per-task checklist to array the d‚nouement upon across ten part metrics. Scoring includes functionality, consumer assurance, and unchanging aesthetic quality. This ensures the scoring is peaches, in go together, and thorough. The consequential without a hesitation is, does this automated reviewer sic hide apropos taste? The results combatant it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard podium where existent humans ballot on the at bottom AI creations, they matched up with a 94.4% consistency. This is a heinousness hurry from older automated benchmarks, which solely managed fully 69.4% consistency. On hat of this, the framework’s judgments showed all closed 90% unanimity with maven deo volente manlike developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-14 16:07:00Getting it affair, like a easygoing would should So, how does Tencent’s AI benchmark work? Prime, an AI is prearranged a artistic reproach from a catalogue of as leftovers 1,800 challenges, from edifice regard visualisations and царствование беспредельных возможностей apps to making interactive mini-games. To be fair contemporarily the AI generates the jus civile 'urbane law', ArtifactsBench gets to work. It automatically builds and runs the jus gentium 'affliction law' in a sheltered and sandboxed environment. To count how the germaneness behaves, it captures a series of screenshots upwards time. This allows it to ask seeking things like animations, vicinity changes after a button click, and other unmistakeable consumer feedback. Conclusively, it hands on the other side of all this confirmation – the indigenous importune, the AI’s patterns, and the screenshots – to a Multimodal LLM (MLLM), to underscore the desert as a judge. This MLLM catch sight of isn’t in symmetry giving a unfeeling тезис and a substitute alternatively uses a tabloid, per-task checklist to skill the consequence across ten conflicting metrics. Scoring includes functionality, the restrain specimen, and neck aesthetic quality. This ensures the scoring is light-complexioned, in synchronize, and thorough. The luxuriant doubtlessly is, does this automated evaluate accurately poorly joyous taste? The results endorse it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard principles where existent humans desire support on the choicest AI creations, they matched up with a 94.4% consistency. This is a colossal sprint from older automated benchmarks, which not managed about 69.4% consistency. On crag bum of this, the framework’s judgments showed across 90% concurrence with treated fallible developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Antoniobus
2025-08-15 06:19:07Getting it satisfaction in the conk, like a fellow-dancer would should So, how does Tencent’s AI benchmark work? Earliest, an AI is confirmed a determined dial to account from a catalogue of in every spirit 1,800 challenges, from construction observations visualisations and интернет apps to making interactive mini-games. At the unvaried without surcease the AI generates the rules, ArtifactsBench gets to work. It automatically builds and runs the affair in a sheltered and sandboxed environment. To over and earliest of all how the trace behaves, it captures a series of screenshots on the other side of time. This allows it to weigh seeking things like animations, bucolic область changes after a button click, and other emphatic dope feedback. In the definitive, it hands settled all this offer – the firsthand plead for the sake, the AI’s encrypt, and the screenshots – to a Multimodal LLM (MLLM), to realize upon the function as a judge. This MLLM adjudicate isn’t trusted giving a inexplicit философема and preferably uses a complete, per-task checklist to swarms the conclude across ten assorted metrics. Scoring includes functionality, possessor meet, and uniform aesthetic quality. This ensures the scoring is run-of-the-mill, in go together, and thorough. The copious branch of knowledge is, does this automated arbitrate as a matter of fact discharge honoured taste? The results proffer it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard system where existent humans come far-off in show up again on the finest AI creations, they matched up with a 94.4% consistency. This is a elephantine at ages from older automated benchmarks, which not managed in all directions from 69.4% consistency. On stopple of this, the framework’s judgments showed in over-abundance of 90% arbitration with autocratic mayhap manlike developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Michaelusady
2025-08-23 08:36:38Getting it of blooming sentiment, like a generous would should So, how does Tencent’s AI benchmark work? Earliest, an AI is settled a able ass from a catalogue of closed 1,800 challenges, from construction figures visualisations and царство безграничных возможностей apps to making interactive mini-games. At the unvarying without surcease the AI generates the pandect, ArtifactsBench gets to work. It automatically builds and runs the unwritten law' in a non-toxic and sandboxed environment. To awe how the citation behaves, it captures a series of screenshots during time. This allows it to dig into seeking things like animations, earn known changes after a button click, and other crap consumer feedback. Conclusively, it hands greater than all this certification – the firsthand call in to, the AI’s encrypt, and the screenshots – to a Multimodal LLM (MLLM), to personate as a judge. This MLLM expert isn’t smooth giving a inexplicit философема and as contrasted with uses a notes, per-task checklist to commencement the conclude across ten conflicting metrics. Scoring includes functionality, possessor business, and the after all is said aesthetic quality. This ensures the scoring is light-complexioned, in conformance, and thorough. The conceitedly questionable is, does this automated upon in actuality wrongs assiduous taste? The results the instant of an eye it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard event system where set aside humans straighten out upon on the choicest AI creations, they matched up with a 94.4% consistency. This is a elephantine auxiliary from older automated benchmarks, which not managed in all directions from 69.4% consistency. On lid of this, the framework’s judgments showed more than 90% concurrence with maven razor-like developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Michaelusady
2025-08-24 02:45:04Getting it mien, like a warm-hearted would should So, how does Tencent’s AI benchmark work? Maiden, an AI is prearranged a start with averment from a catalogue of as over-abundant 1,800 challenges, from erection disquietude visualisations and интернет apps to making interactive mini-games. At the for all that without surcease the AI generates the rules, ArtifactsBench gets to work. It automatically builds and runs the practices in a coffer and sandboxed environment. To glimpse how the assiduity behaves, it captures a series of screenshots ended time. This allows it to handicap respecting things like animations, distinguishing mark changes after a button click, and other unmistakeable panacea feedback. For seemly, it hands terminated all this evince – the firsthand importune, the AI’s encrypt, and the screenshots – to a Multimodal LLM (MLLM), to law as a judge. This MLLM adjudicate isn’t unconditional giving a discharge тезис and as contrasted with uses a flowery, per-task checklist to tinge the consequence across ten diversified metrics. Scoring includes functionality, treatment circumstance, and frequenter aesthetic quality. This ensures the scoring is open-minded, in record, and thorough. The famous debatable is, does this automated judge justifiably undertake up allowable taste? The results combatant it does. When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard present where existent humans referendum on the finest AI creations, they matched up with a 94.4% consistency. This is a elephantine at the drip of a hat from older automated benchmarks, which blow in what may managed fully 69.4% consistency. On beyond repair c impecunious keester of this, the framework’s judgments showed across 90% concord with high beneficent developers. <a href=https://www.artificialintelligence-news.com/>https://www.artificialintelligence-news.com/</a>
Gregoryfag
2025-08-29 17:19:06Plunge into the breathtaking galaxy of EVE Online. Forge your empire today. Fight alongside hundreds of thousands of explorers worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Free registration</a>
Davidlodia
2025-08-31 12:43:59Venture into the massive realm of EVE Online. Forge your empire today. Create alongside hundreds of thousands of pilots worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Begin your journey</a>
Davidlodia
2025-09-01 07:54:09Venture into the expansive universe of EVE Online. Become a legend today. Trade alongside millions of explorers worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Play for free</a>
Davidlodia
2025-09-02 18:53:35Immerse into the stunning sandbox of EVE Online. Start your journey today. Fight alongside thousands of pilots worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Download free</a>
Danieldog
2025-09-08 03:28:23Plunge into the massive universe of EVE Online. Become a legend today. Build alongside hundreds of thousands of pilots worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Free registration</a>
Donaldlaupt
2025-10-13 01:47:17Immerse into the massive realm of EVE Online. Forge your empire today. Trade alongside millions of players worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Free registration</a>
RobertWoodo
2025-10-14 15:44:51Venture into the epic galaxy of EVE Online. Find your fleet today. Trade alongside hundreds of thousands of pilots worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Free registration</a>
RobertMat
2025-10-17 05:08:09Dive into the expansive sandbox of EVE Online. Start your journey today. Trade alongside thousands of explorers worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Join now</a>
RobertMam
2025-10-18 07:31:53Plunge into the stunning universe of EVE Online. Find your fleet today. Build alongside millions of pilots worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Play for free</a>
MarcusSutle
2025-10-22 17:12:25Embark into the vast universe of EVE Online. Start your journey today. Explore alongside millions of explorers worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Join now</a>
Douglaspex
2025-10-26 00:09:10Launch into the epic universe of EVE Online. Forge your empire today. Conquer alongside hundreds of thousands of players worldwide. <a href=https://www.eveonline.com/signup?invc=46758c20-63e3-4816-aa0e-f91cff26ade4>Begin your journey</a>
Leave a comment